*Disclaimer: I am not a computer scientist¶
A few words about my background¶
What this talk is about¶
- Using abstraction to manage complexity
The hardest part of programming?¶
Examples of complexity¶
- Major multi-million dollar projects without single working line of code
Development of the website that would process online enrollments was done by Oracle Corporation and managed by the state of Oregon rather than an independent systems integrator.[11] The project was plagued by numerous management and technological issues, and though the website was supposed to begin processing enrollments on October 1, by mid-October, it was unable to process any enrollments.[12]
As of mid-December 2013, the deadline for enrollment for coverage beginning January 1, the state had spent nearly \$160 million and the site still could not process online enrollments.[11] Governor John Kitzhaber informed Oregon residents that they should obtain a paper application and mail it in to obtain coverage.
- Radiation overdoses
The Therac-25 was a radiation therapy machine produced by Atomic Energy of Canada Limited...
It was involved in at least six accidents between 1985 and 1987, in which patients were given massive overdoses of radiation. Because of concurrent programming errors, it sometimes gave its patients radiation doses that were thousands of times greater than normal, resulting in death or serious injury.[2] These accidents highlighted the dangers of software control of safety-critical systems...
A commission concluded that the primary reason should be attributed to the bad software design and development practices, and not explicitly to several coding errors that were found. In particular, the software was designed so that it was realistically impossible to test it in a clean automated way.[5]
- The list goes on and on
How do we deal with complexity?¶
- Make it simple
Elegance is power cloaked in simplicity -- Robins and Beebe, classic shell scripting
Algorithms¶
A motivating problem¶
Find out if an element is in your data.
Why we care¶
- Databases
How is our data stored?¶
- Lots of possibilities: str, list, dict, tuple, set etc.
Does our list contain a certain element?¶
from random import randrange
def get_rand_list(n=10, upper_num=100):
"""Returns a list of random numbers.
Parameters
----------
upper_num: int
Sets the lower and upper bound for our random numbers
n: int
Sets the number of elements in our list.
Returns
-------
list
"""
return [randrange(upper_num) for x in range(n)] # returns a list of n random numbers
lst = get_rand_list()
print("list = ", lst)
####### Exercise #######
def list_search(elem, lst):
""" Returns True if elem is in lst and False otherwise."""
return elem in lst
####### Tests #######
def list_search_pass_test():
lst = [1,2,3,4]
assert list_search(3, lst) == True
def list_search_fail_test():
lst = [1,2,3,4]
assert list_search(6, lst) == False
lst = get_rand_list()
elem = 71
print("Element is in list: {bool}".format(bool=list_search(elem, lst)))
How can we check?¶
Start at the beginning and check every element (brute force).
####### Exercise #######
def brute_force_search(elem, lst):
"""Returns True if elem is in lst and False otherwise."""
bool_lst = [elem for num in lst if elem == num]
return any(bool_lst) # returns false if bool_lst is empty
####### Tests #######
def brute_force_search_pass_test():
lst = [1,2,3,4]
assert brute_force_search(3, lst) == True
def brute_force_search_fail_test():
lst = [1,2,3,4]
assert brute_force_search(6, lst) == False
brute_force_search_pass_test()
brute_force_search_fail_test()
Brute force method¶
- best case?
- worst case?
- what if the list is randomized? What's our average performance?
- Exercise using timeit
- How does each case depend on the number of elements in the list?
| Prefix | 1000m | 10n | Decimal | English word | Since[nb 1] | ||
|---|---|---|---|---|---|---|---|
| Name | Symbol | Short scale | Long scale | ||||
| 10000 | 100 | 1 | one | – | |||
| deci | d | 1000−1/3 | 10−1 | 0.1 | tenth | 1960 (1795) | |
| centi | c | 1000−2/3 | 10−2 | 0.01 | hundredth | 1960 (1795) | |
| milli | m | 1000−1 | 10−3 | 0.001 | thousandth | 1960 (1795) | |
| micro | μ | 1000−2 | 10−6 | 0.000001 | millionth | 1960 (1873) | |
| nano | n | 1000−3 | 10−9 | 0.000000001 | billionth | thousand millionth | 1960 |
Idea: what if our list was sorted?¶
- A smarter search algorithm?
Binary Search¶
We consider three cases:
- If the target equals data[mid], then we have found the item we are looking for, and the search terminates successfully.
- If target < data[mid], then we recur on the first half of the sequence, that is, on the interval of indices from low to mid − 1.
- If target > data[mid], then we recur on the second half of the sequence, that is, on the interval of indices from mid + 1 to high. An unsuccessful search occurs if low > high, as the interval [low, high] is empty.
def binary_search(item, alist):
if len(alist) == 0:
return False
else:
midpoint = len(alist)//2
if alist[midpoint]==item:
return True
else:
if item<alist[midpoint]:
return binary_search(item, alist[:midpoint])
else:
return binary_search(item, alist[midpoint+1:])
testlist = [0, 1, 2, 8, 13, 17, 19, 32, 42,]
print(binary_search(3, testlist))
print(binary_search(13, testlist))
#lst = sorted(get_rand_list())
lst = get_rand_list()
lst
binary_search(68, sorted(lst))
- Exercise using timeit
- How does each case depend on the number of elements in the list?
Divide and conquer¶
problems with comparing binary search to brute force¶
- number of items in list
- hardware
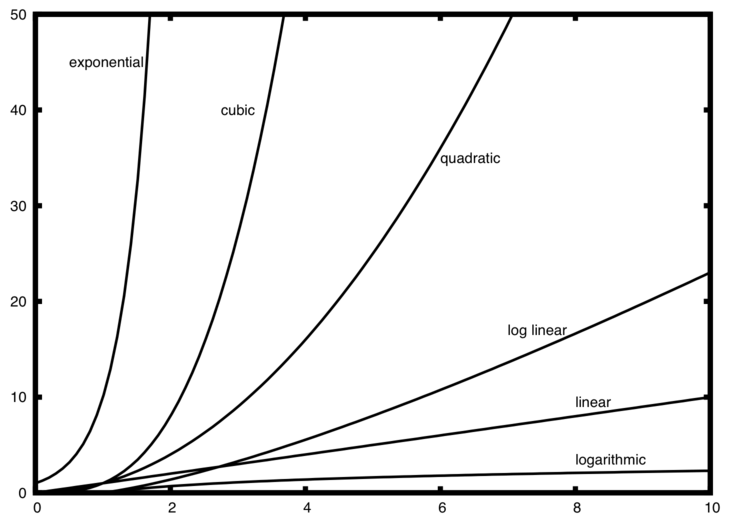
Big O notation¶
from time import time
def func_timer(func, *params, verbose=False):
"""Takes in a function and some parameters to the function and returns the execution time"""
start = time()
func(*params)
t = time() - start
if verbose:
print('function {func_name} took {time} seconds to complete given parameters'.format(
func_name=func.__name__, time=t))
return t
elem, n = 50, 10000
print(func_timer(brute_force_search, elem, get_rand_list(n), verbose=True))
print()
print(func_timer(list_search, elem, get_rand_list(n), verbose=True))
print()
print(func_timer(binary_search, elem, sorted(get_rand_list(n)), verbose=True))
In order to visualize the time complexity of our search algorithms, we'll generate a list of random lists sampled from length 1 to n.¶
We will map our timing function and the search function to each list in our list and then plot the length of the list against its runtime.¶
%matplotlib inline
from matplotlib import pyplot as plt
def sort_compare(max_size, num_samples, func):
"""Returns two lists corresponding to the lengths of random lists and the runtime
execution of function func on those lists.
"""
assert max_size > num_samples
delta = max_size // num_samples # uses the floor function to get difference between each sample.
lst_lengths = [delta*x for x in range(num_samples)]
lst_of_rand_lsts = [get_rand_list(x) for x in lst_lengths]
func_times_lst = [func_timer(func, 50, lst) for lst in lst_of_rand_lsts]
return lst_lengths, func_times_lst
def subplot_generator(lst_lengths, func_times_lst):
plt.plot(lst_lengths, func_times_lst, 'bo')
return
def sort_plotter(max_size, num_samples, *funcs):
"""Plots functions vs execution time.
Details
-------
Creates plots of each function in *funcs wrt
execution time by sampling num_samples lists of incremental
length up to length max_size.
Parameters
----------
max_size: int
The length of the final list sampled.
num_samples: int
The number of times to sample_the function.
*functs: iterator
An iterator containing the functions we wish to sample.
Returns
-------
plots: matplotlib.pyplot
Returns subplots with the length of the sampled
list as the x-axis, and the average runtime of the
function over the list using timeit.
NOTE: timeit defaults to 1000 function calls.
"""
print(type(funcs))
# sort_compare(max_size, num_samples, func)
return
lst_lengths, func_times_lst = sort_compare(10000, 1000, brute_force_search)
subplot_generator(lst_lengths, func_times_lst)

lst_lengths, func_times_lst = set_compare(10000, 1000, set)
subplot_generator(lst_lengths, func_times_lst)

lst_lengths, func_times_lst = sort_compare(10000, 1000, binary_search)
subplot_generator(lst_lengths, func_times_lst)

- Brute force: O(n)
- Binary search: O(log(n))